Les enjeux des méthodes de segmentation ou de clustering sont majeurs pour le marketing, et particulièrement pour le marketing digital. Avec le développement des techniques de production/récupération/stockage de la donnée, la masse d’information n’a jamais été aussi importante et paradoxalement n’a jamais été aussi dure à interpréter. C’est là que les méthodes de segmentation et de clustering entrent en scène.
Avant d’aller plus loin, quelques éclaircissements sur du vocabulaire : dans la suite de l’article, le terme « segment » fera référence au résultat d’une segmentation, alors que le terme « groupe » est utilisé pour le résultat d’un clustering.
Maintenant que nous parlons le même langage, allons-y !
La segmentation est un procédé qui permet de classer des clients en se basant sur des similarités, le clustering lui vise à trouver des similarités au sein des clients pour pouvoir les grouper. Même si la finalité est la même les méthodes pour arriver à une séparation des clients diffèrent.
Confus ? Quelques explications.
Qu’est ce que la segmentation de la data ?
Le principe d’une segmentation est de séparer les clients selon des critères déterministes. Si on souhaite classer 100 personnes selon si elles sont gauchères ou droitières, il n’y a pas de décision laissé à l’aléatoire, en effet une personne est soit gauchère soit droitière (on ne prend pas en compte ici les ambidextres pour ceux d’entre vous qui cherchent la petit bête).
Par exemple dans le secteur de la joaillerie, une segmentation Homme/Femme peut par exemple être pertinente tant pour analyser les comportements d’achat (ex : meilleur taux de conversion chez les Femmes) que pour adapter le message et la proposition adressés aux clients / clientes (ex : campagnes d’emails exclusivement réservées aux clientes).
L’avantage de la segmentation vient de sa simplicité de mise en place. Identifier des segments d’individus est facile lorsque l’on sait ce que l’on cherche : on peut imaginer regarder le segment des Femmes de 18 à 25 ans, habitant en France qui sont venues sur mon site entre 20h et 22h.
En contrepartie, la segmentation souffre d’un inconvénient majeur, elle suppose une connaissance à priori des variables de segmentation. En effet, si le facteur déterminant dans la classification de vos clients est l’utilisation ou non d’une tablette et que vous n’avez pas pensé à regarder ce segment en particulier vous pouvez passer à côté d’un comportement d’achat important pour votre business (toujours pour notre exemple imaginaire, il n’est pas forcement intuitif de penser que les acheteurs de bijoux utilisent en majorité des tablettes !). Avec la démocratisation du Big Data, les clients peuvent avoir des centaines de caractéristiques (temps passé sur le site, navigateur utilisé, marque préférée, etc) et devient donc vraiment difficile pour une personne de trouver des liens entre chacune de ces caractéristiques.
C’est là que le clustering prend toute son importance.
Qu’est ce que le clustering de la data ?
Pour comprendre le principe du clustering, reprenons nos 100 personnes. Cette fois ci on souhaite faire des groupes selon la taille de la personne. Tout un lot de questions se posent alors pour répartir ces individus en groupes : A partir de quelle taille est-on « grand »/ « petit » ? Ces notions changent-elles selon l’échantillon à disposition ? Un partage en deux groupes suffit-il ? Si non, combien de groupe faut-il ? Bref, l’intuition trouve vite ses limites et il faut laisser parler la data !
Les méthodes de clustering sont diverses mais elles se basent principalement sur des algorithmes de machine learning qui cherchent des relations de proximités entre les individus pour ensuite en faire des groupes (ou clusters). L’objectif de ces algorithmes est donc de créer des groupes les plus homogènes en leur sein mais les plus hétérogènes entre eux.
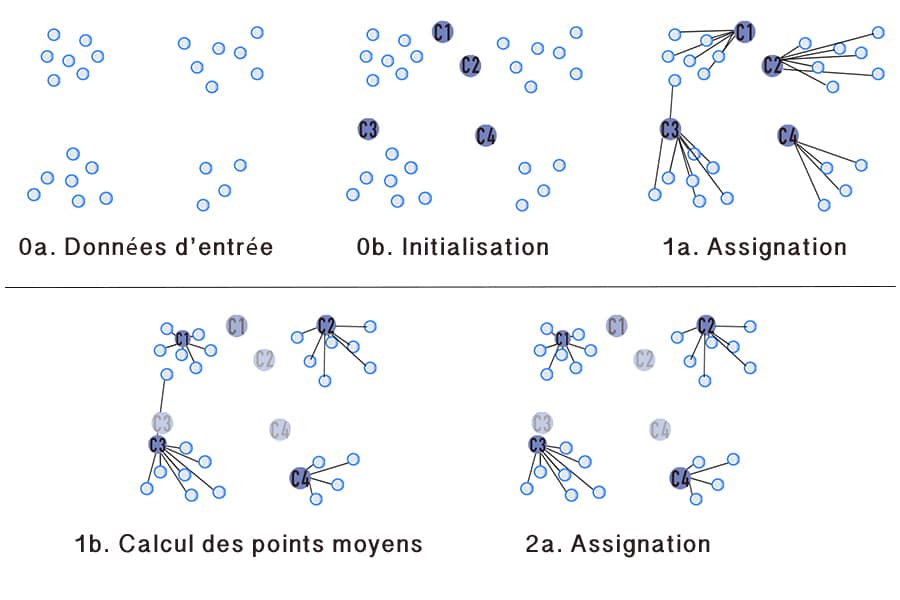
Ces méthodes ont un avantage majeur, celui de ne pas prendre d’apriori sur les variables discriminantes et trouve ses réponses directement dans les data. C’est là où réside la valeur des méthodes de clustering, elles permettent d’explorer des dizaines (et dans certains cas centaines) de variables et de mettre en évidence des comportements négligés et des relations insoupçonnés.
L’importance de ces modèles est cruciale pour les marketeurs, puisque la découverte d’un nouveau cluster de clients et les habitudes d’achat associées peut permettre de faire des économies en ciblant plus finement ce cluster et ainsi acquérir un nouveau marché et mieux connaitre ses clients.
Wizaly propose des segmentations classiques respectueuses de la RGPD : nouveaux visiteurs / anciens visiteurs / nouveaux clients / anciens clients, ect… Mais permet également, par le volume et la qualité de sa collecte de données, une approche complémentaire via le clustering. L’objectif est ici de pouvoir identifier de nouveaux comportements consommateurs non appréhendables avec une segmentation classique.
A l’instar de notre approche sur l’attribution qui s’affranchit de la vision a priori des modèles rules based, le clustering permet donc d’envisager le comportement client avec une approche 100% data driven.


